Bir iş arama sitesinde “React geliştirici” aradığınızda neden “Frontend geliştirici” ilanları da çıkıyor? Ya da ChatGPT’ye “kedi” dediğinizde neden “köpek”, “hayvan”, “evcil” gibi ilişkili kavramları anlıyor? Modern AI’ın bu büyüsünün arkasında embeddings (vektörel temsiller) yatıyor. Onun için bu kavram ile başlamak en mantıklısı olacaktır.
Embeddings “gömmeler” veya “gömülmeler” olarak Türkçeye çevrilmiş kimi kaynaklarda. ChatGPT gibi dil modellerine sorunca bazen bu çeviriyi kullanıyor. Bu kavramı Türkçe’leştirmek için şimdilik “vektörel temsiller” demeyi tercih ediyorum. Embeddings yani vektörel temsiller kelimelerin sayılara dönüşmüş halidir.
Başlangıç: Klasik Arama ve N-gram Analizinin Sınırları
Örneğin bir arama motorlarını düşünün sizin verdiğiniz dökümanlardan indexler üretirler. Arama indexler üzerinden gerçekleşir ve sizi asıl bulmak istediğiniz kaynağa yönlendirirler. Bunu yapmak için bazı yöntemler kullanırlar, en popülerlerinden birisi n-gram analizi.
N-gram Analizi Nedir?
n herhangi bir sayı olabilir (1, 2, 3…) ve herhangi bir cümle formundaki kelime sayısını ifade eder:
- “Haydi Abbas” → 2-gram
- “Haydi Abbas vakit” → 3-gram
Bir sonraki kelimenin “tamam” olabileceğini bulmak için bir olasılık hesabı yapılır. Arama yapacağınız indexdeki tüm metinler için bu olasılık hesaplanır ve en yüksek skora sahip sonuçlar size döner.
Güncel arama motorlarında veya otomatik tamamlama gibi araçlarda sıkça kullanılır, temelde bir sonraki kelimeyi sizin elinizdeki verilere (indexe) göre istatistiksel olarak tahmin etmeye çalışır. Bunu yaparken de bu kelimenin daha önce ne kadar sıklıkla geçtiğini bulmaya çalışır.
Kod Örneği: N-gram Tabanlı Arama
Aşağıdaki örnekte N-gram analizinin nasıl çalıştığını ile ilgili basit bir örnek görebilirsiniz:
Terminalden:node sample-1-ngram.jsile kodu çalıştırarak çıktıyı görebilirsiniz.
Yukarıdaki N-gram arama motoru şöyle çalışıyor: Her iş ilanının metnini alıp 2’li ve 3’lü kelime grupları oluşturuyor (örneğin “Senior React Developer” → “senior react”, “react developer”). Bu grupları bir Map’de saklayıp kaç kez geçtiğini sayıyor. Arama yaparken tüm grupları tarayıp aranan kelimeyi içerenleri frekansa göre sıralıyor. Tahmin özelliği ise “react geliştirici” gibi 2 kelimeyle başlayan 3’lü grupları bulup 3. kelimeleri öneriyor. “react geliştirici” birden fazla ilanda geçtiği için 2x-3x frekansla görünüyor ve arama sonuçlarında üst sıralara çıkıyor. Performans olarak da neredeyse sorunsuz. Sorun şu ki anlamsız aynı kelimelerin sürekli tekrar ettiği dökümanlar daha üst sıralarda yer alabiliyor. Anlama değil tamamen tekrar etme sıklığına bakıyor.
Kritik Problem: Semantik Yakınlık
Burada anlamsal/semantik bir yakınlığa bakılmaz. Bunun anlamı şu: eğer sizin metinlerinizde “react” ve “frontend” kelimeleri sıklıkla birlikte geçmiyorsa, sistem “react geliştirici”nin aslında bir “frontend geliştirici” olduğunu anlayamaz.
Bir kelime çok tekrarlanıyor ve sıklıkla birlikte (n-li birimlerde) kullanılıyor diye daha yüksek skor alır ve üst sıralarda görünür olur. Ama bu yaklaşımın temel sorunu: anlamsal ilişkileri yakalayamaması. Burası bir aydınlanma noktası!
Dil Modelleri Kelimeleri Nasıl Kıyaslıyor?
Şu an bir problem belirdi. Bizim kelimeleri anlamlarına göre kıyaslamamız ve yakın anlamlı olanları yakalayabilmemiz gerekiyor. İki şeyin en kolay kıyaslama yöntemi onu sayısal olarak ifade etmektir.
7, 11 ve 23 rakamlarını kıyaslamanız kolaydır:
- 11, 7’den büyük, 23’ten küçüktür
- 11, 7’ye 23’ten daha yakındır
Ben burada:
- 7’ye “geliştirici”
- 11’e “frontend”
- 23’e “UI”
demek istiyorum. Yani “frontend geliştirici” kavram olarak daha yakın, “UI geliştirici” kavram olarak daha uzaklar. Diğer taraftan “frontend”, “UI”a kavram olarak daha yakın.
Şimdi artık kıyaslamamı bu rakamlara göre yapabilirim. Benim bu üç kelimelik külliyatımda (corpus) “Frontend” dedikten sonra bir sonraki kelimenin “geliştirici” olarak gelmesi beklediğim bir şey olacaktır.
Kod Örneği: Basit Sayısal Kıyaslama
=== Semantik Mesafe Analizi ==="geliştirici" - "frontend" mesafesi: 4"geliştirici" - "ui" mesafesi: 16"frontend" - "backend" mesafesi: 4"frontend" - "ui" mesafesi: 12
=== 'frontend'e benzer kelimeler ===fullstack: mesafe 2geliştirici: mesafe 4backend: mesafe 4Bu çok basit bir skaler sayısal kıyaslama örneği, kompleks vektörel temsillerin temelini anlamamız için bence önemli. Burada rastgele sayılar verdik kelimelere ve bu kelimeleri birbiri ile kıyasladık. Sayıları rastgele verdiğimizi unutmayın! Bu basit örnek ileride göreceğimiz 300 boyutlu uzayda yapılanın 1 boyutlu prototipi. Aynı mantık çok daha sofistike matematik ile uygulanacak.
Vektörel Temsillerin Doğuşu
Vektörel temsiller ise tam bu noktada işimize yarıyor. Yukarıda biz bir kelimeyi bir sayı ile temsil ediyorduk basitçe. Fakat derin öğrenme dünyası iki boyutlu lineer bir dünya değil. Her yöne gidebilen çok boyutlu bir kelime evreninden bahsedebiliriz.
Buradaki “boyut” kavramı önemli, akıldan çıkarılmaması gereken bir kavram.
Dil modellerinin yapı taşı kelimeler, kelimeleri oluşturan heceler veya heceleri oluşturan harfler. İşte bu yapıtaşları çok boyutlu vektörlerle temsil edilir ve vektör temsilleri üretilir. Modeller bu kompleks vektörleri bizim basitleştirdiğimiz sayısal temsiller gibi kullanır ve kıyaslama için kullanır.
Örneğin aşağıdaki vektör “geliştirici” kelimesini temsil eden yeni bir vektör olarak düşünebiliriz:
geliştirici = [4, 3, 9]Daha önce “7” sayısı ile basitçe temsil ettiğimiz kelimeyi artık üç boyutlu yani üç farklı özellik boyutunda temsil ediyor. Böylelikle artık iki boyutlu bir kıyaslama yerine çok boyutlu bir dünyada binlerce kelime ile daha hassas bir kıyaslama yapabilecek hale geliyoruz. Özellik boyutundan neyi kast ettiğimi biraz daha açalım. Örneğin ilk boyut teknik seviyeyi, ikinci boyut deneyim yılını, üçüncü boyut maaş seviyesini temsil edebilir. Bu sayede yukarıdaki geliştirici vektörünü “frontend = [6, 2, 7]” ile karşılaştırırken hangi açılardan benzer hangi açılardan farklı olduklarını görebiliyoruz.
Gerçekte kullanılan embedding’lerde bu mantık çok daha büyük ölçekte işlenir. GPT ve BERT gibi modellerde kelimeler genelde yaklaşık 768 boyutlu (bu değer openai embedding-3-large için 3072) vektörlerle temsil ediliyor. Ama bu boyutların her biri elle tanımlanmış özellikler değil. Model milyarlarca metin üzerinde eğitilirken kendi kendine öğrendiği soyut özellikler. Örneğin boyut 23 belki cinsiyet ayrımını (kral/kraliçe), boyut 156 zaman kavramlarını (dün/yarın), boyut 341 duygu durumunu yakalıyor olabilir. Ama tam olarak her boyutun neyi temsil ettiğini bilmiyoruz. Model sadece “bu 768 sayı kombinasyonu bu kelimeyi en iyi şekilde temsil ediyor” diyor ve bu soyut temsil sayesinde kelimeler arasındaki karmaşık anlamsal ilişkileri yakalayabiliyor. Bu sebeple örneğin OpenAI text-embedding ile ürettiğiniz 1536 elemanlı bir vektör ile başka bir modelden ürettiğiniz aynı elemanlı bir vektörü kıyaslayamazsınız. Vektör boyutları aynı olsa da boyutlar farklı kavramları temsil edebilir.
Burada kafa karıştırıcı bir “şey” var. Sanki embedding üretilecek metin uzadıkça boyut da uzayacak daha büyük boyutlu vektörler elde edilmesi gerekecek gibi düşünebilirsiniz. Aslında öyle değil. Tüm bir kitabı da girdi olarak verseniz, bir kaç kelimeyi de, vektörel temsili oluşturduğunuz boyut her zaman sabittir.
“Bineyim bir boğaziçi vapuruna günün birinde. Bebek’le Arnavutköy önlerinde arka taraftaki oturduğum kanapeden kalkayım, etrafıma bakayım” gibi bir paragraf da, “boğaziçi vapuru” gibi iki kelimelik kısa bir ifade de, “arka taraftaki oturduğum kanape” gibi bir cümle de hepsi aynı boyutlu, örneğin 768 elemanlı vektöre dönüştürülüyor.
Peki model bunu nasıl yapıyor? İlk önce metni kelime parçalarına ayırıp her birini ayrı ayrı vektöre çeviriyor. Sonra bu farklı sayıdaki vektörleri tek bir vektöre birleştirmesi gerekiyor. En basit yöntem ortalama almak. Tüm kelime vektörlerini toplayıp sayılarına bölmek. Ama modern modeller daha akıllı: attention mekanizması kullanarak hangi kelimelerin daha önemli olduğunu belirliyor ve o kelimelere daha fazla ağırlık veriyor. Böylece “boğaziçi” ve “vapuru” kelimelerinin ağırlığı, “bir” ve “günün” gibi yardımcı kelimelerden daha fazla oluyor.
Bu sabit boyut özelliği çok güçlü imkanlar sunuyor. Artık kısa bir arama sorgusu ile uzun belgeleri karşılaştırabiliyorsunuz, farklı uzunluktaki metinleri aynı kategorilere koyabiliyorsunuz. Model her metnin “anlamsal parmak izi”ni aynı boyutta çıkarttığı için, uzunluk farkı etmiyor, dolayısıyla önemli olan içerikteki anlam, semantik.
Bir/az Matematik
Burada bir adım geri atmalıyız. Tensör, matris, vektör ve skaler. Bunları matematiksel modellerin primitifleri gibi düşünebiliriz ve hepsinin temel tipi tensördür. Unix’de her şeyin dosya olması gibi. Mekanikte kullanılan gerilme tensörü de NLP’deki tensör de aslında aynı temsildir. Aynı veri tipleri ile işlem yaptığımız için sadece dil modellerine değil farklı ihtiyaçlara evrilebilir.
Skaler
Bunu boyutsuz bir nokta olarak düşünebiliriz. Örneğin 7.
Vektör
Yukarıdaki gibi [4, 3, 9] vektörü. Artık bir noktadan çıktık, bizim kelime uzayımızda bir konuma yerleştirdik.
Matris
Bir excel tablosu veya kareli defter gibi düşünebiliriz. Her bir satırda bir vektör ve dolayısıyla bir kelime temsil ediyoruz. Böylelikle bir kaç kelimeyi veya bir cümleyi tek bir matris olarak ifade edebiliriz:
frontend => [1 3 4]geliştirici => [4 3 9]
"frontend geliştirici" = [1 3 4] [4 3 9]Tensor
Tensörler, birden çok vektörü alıp bunları bir sayıya (skalere) dönüştüren fonksiyonlar olarak düşünülebilir. Bu dönüşüm sırasında, her bir vektör üzerinde ayrı ayrı doğrusal işlemler yapılır. Boyut sayısı arttıkça temsiller daha zor kafada canlandırılabilir hale geliyor. İnsanın somut düşünce sınırlarına geliyoruz fakat matematiksel temsillere teorik olarak bir sınır tanımıyor. Kelimeler üzerinden gidiyor olsak da bu matrisler veriyi temsil ettiği için bir görsel veya ses olabilir. Hepsi sayısal olarak ifade edilebilir.
Ana konumuz matematik temelleri değil fakat ihtiyaç duyanlar, tekrar etmek isteyenler 3Blue1Brown’un video serisine göz atabilir, çok iyi bir kaynak.
Kod Örneği: Vektör İşlemleri
Bu kod bloğu modern embeddings’in matematiksel temelini oluşturan vektör işlemlerini gösteriyor.
dotProduct() Metodu
Nokta çarpımı, ML için hayati derecede önemlidir; aslında LLM’lerin temel yapı taşı diyebiliriz. GPU bu temel işlemi hızlı ve yüksek paralellikte yapabildikleri için LLM devrimini mümkün kılmıştır. Nokta çarpımı aslında iki vektörün ne kadar “aynı yönde” olduğunu ölçüyor. Matematiksel olarak her elemanı çarpıp topluyoruz: [4,3,9] · [1,5,2] = (4×1) + (3×5) + (9×2) = 4 + 15 + 18 = 37. Bu işlem önemli çünkü model eğitimi sırasında sürekli kelime vektörleri arasında nokta çarpımı hesaplanıyor. Yüksek nokta çarpımı benzer yönde olan vektörleri, düşük değer ise farklı yönlere bakan vektörleri gösteriyor.
magnitude() Metodu
Vektörün uzunluğunu hesaplıyor, yani orijin noktasından vektörün ucuna kadar olan Öklid mesafesini buluyor. Bu hesaplama klasik lise matematiği, √(x₁² + x₂² + x₃² + ...) formülü ile yapılıyor. Magnitude normalizasyon için kritik çünkü farklı büyüklükteki vektörleri kıyaslarken sadece yönlerini değil büyüklüklerini de hesaba katmamız gerekiyor. Vektör büyüklükleri farklı olabileceği için kosinüs benzerliği hesaplarken magnitude ile böleriz. Çünkü bir kelimenin ne kadar sık kullanıldığını veya vektörünün ne kadar “uzun” olduğunu göz ardı edip, sadece ve sadece anlamsal özüne, yani diğer kavramlarla olan ilişkisel yönüne odaklanıyoruz.
cosineSimilarity() Metodu
İki vektör arasındaki açının kosinüsünü hesaplıyor. Bu açı 0° ise kosinüs 1 (tamamen benzer), 90° ise kosinüs 0 (hiç benzemez), 180° ise kosinüs -1 (tamamen zıt) oluyor. Formül: cos θ = (A·B) / (|A|×|B|) şeklinde. Bu metod embedding dünyasının en önemli benzerlik ölçütü çünkü vektör büyüklüklerinden bağımsız olarak sadece yönlere bakıyor. İki kelime vektörü arasında 0.8 kosinüs benzerliği varsa bu kelimeler anlamsal olarak çok yakın demektir.
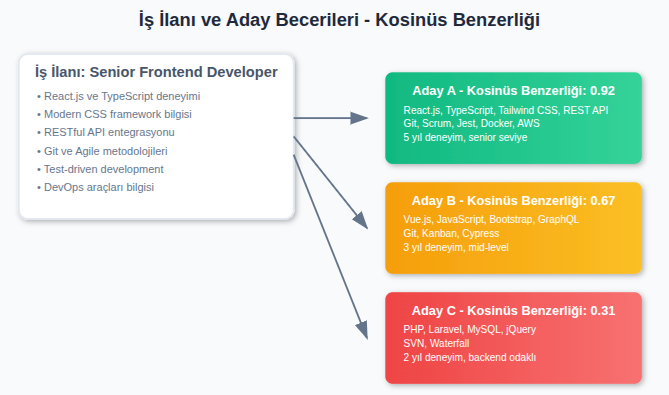
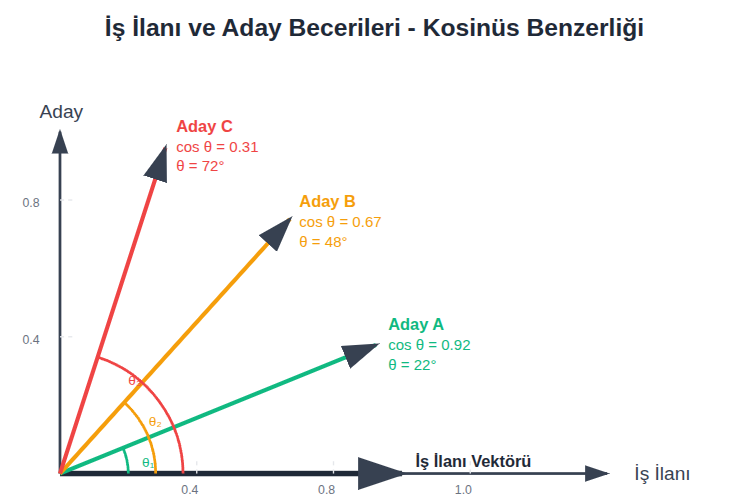 Örneğin yukarıdaki iş ilanı örneğinde, iş ilanı vektörümüz eksene paralel gri ile içaretli vektör.
Örneğin yukarıdaki iş ilanı örneğinde, iş ilanı vektörümüz eksene paralel gri ile içaretli vektör.
- Aday A (0.92): Yüksek oranda benzer.
- Aday B (0.67): Vue.js den dolayı biraz benzer
- Aday C (0.31): EN uzak ihtimal çünkü PHP/Mysql’den ötürü
add() ve subtract() Metodları
Vektör aritmetiğinin temelini oluşturuyor. Çok bilinen “Kral - Erkek + Kadın = Kraliçe” işlemi tam bu metodlarla yapılıyor. Vektör toplama her elemanı tek tek topluyor: [1,3,4] + [4,3,9] = [5,6,13]. Vektör çıkarma da benzer şekilde her elemanı tek tek çıkarıyor. Bu işlemler anlam uzayında geometrik olarak hareket etmemizi sağlıyor.
Word2Vec
Word2Vec, vektörel temsiller için önemli bir dönüm noktası. Yukarıda ilk olarak n-gram ile bir tahmin yapmaya çalışmıştık. Orada kelimelerin ne kadar sık geçtiği bilgisi bizim için önemliydi. Word2Vec’te ise kelimeler arasındaki semantik ilişkinin anlaşılmasına yöneliktir. Kelime olarak da zaten anlatıyor kendisini. Kelimeden vektöre.
Temel Felsefe
Word2Vec’in arkasında distributional hypothesis (dağılımsal hipotez) yatıyor:
Benzer külliyatlarda (corpus) yer alan kelimeler benzer anlamlara gelebilir.”
Bu hipotez ilk olarak 1954’te Zellig Harris tarafından ortaya atılmış: “Benzer anlamda olan kelimeler benzer bağlamlarda geçer.”
Bunun yanında işin biraz daha temeline inmek istersek aşağıdaki sunuma göz atabilirsiniz.
“Know the theory (structuralism) and everything makes sense”
sunumda geçen en sevdiğim söz, yani vektör temsillerinin dil modelleri dünyasında eğer yapısalcılığı anlarsanız diğerleri çorap söküğü gibi gelir diyor özetle. Sunum
Sunumda değinilen Saussure’ün temel argümanı şu: Kelimelerin anlamı kendi başlarına değil, diğer kelimelerle olan ilişkilerinden gelir. “Kral” kelimesinin anlamını anlayabilmek için “kraliçe”, “prens”, “halk” gibi kelimelerle olan farkını bilmemiz gerekir. Saussure’e göre dil sistemi, kelimeler arasındaki karşıtlıklar ve ilişkiler ağıdır.
Google’da 2013’te geliştirilen wod2vec yukarıdaki hipotezi matematiksel olarak hayata geçirdi Makale Linki. Kelimelerin vektör temsilleri, (yüzlerce boyutlu olabilir demiştik) külliyattan öğrenirler ve ilişki kurabilirler. Böylece her bir kelime içerisindeki her bir eleman aslında başka kelimelerin anlamlarına katkıda bulunur. Ana renkleri kullanarak binlerce renk yapabilmek gibi. Benzer anlama gelen kelimeler benzer kelime uzayında benzer bölgelerde yer alırlar.
Vektör İşlemleri
Makalede yer alan örnekten yola çıkarsak; Kral vektöründen bu vektöre Erkek anlamını katan kısımları çıkarıp Kadın anlamlarını katan elemanlar eklersek yaklaşık olarak Kraliçe vektörüne dolayısıyla uzaydaki Kraliçe konumuna ulaşırız:
Kral - Erkek + Kadın ≈ Kraliçe
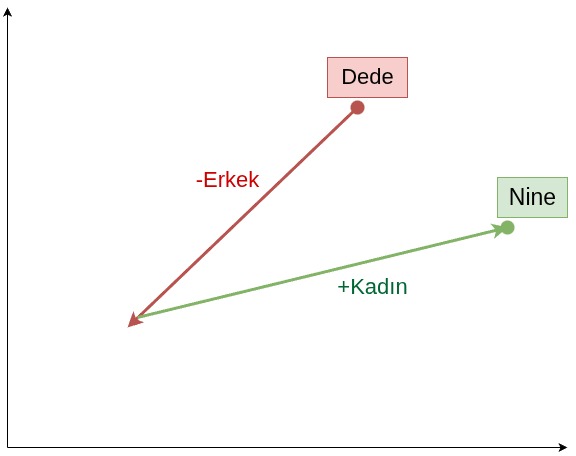
Word2Vec iki yöntem ile bu işi yapar:
- Skip-gram: Verilen kelimeye göre context’i tahmin eder
- CBOW (Continuous Bag of Words): Context’e göre bir kelime tahmin eder
Kod Örneği: Word2Vec Simülasyonu
Bu kod Word2Vec algoritmasının basitleştirilmiş versiyonunu gösteriyor. Gerçek Word2Vec’in temel mantığını anlamamız için her metodun rolünü inceleyelim, burada bi çok kavramı yeri gelmişken açıklıyorum hepsi ileride başka kontekslerde karşımıza çıkacak sadece buraya özgü değil.
Constructor Parametreleri
constructor(vectorSize = 4, windowSize = 2, learningRate = 0.1)Vector Size (Vektör Boyutu)
Yukarıda bahsettiğimiz vektör temsillerinin boyutunu gösteriyor. Vektörün boyutu arttıkça kalitesi artar, fakat bu sonsuz bir kazanım değildir ve bir eşikten sonra artık kazanım olmaz. Genellikle ~300-1000 arası optimal görülür. Yüksek boyutlu olmayacağı anlamına gelmez.
Learning Rate (Öğrenme Adımı)
Tüm parametreler içerisinde en çok üzerinde düşünülen, uygun değerin bulunması en çok vakit alan parametre bu. Optimizasyon kısmında daha çok konuşacağımız bu parametreyi şimdilik “adım” gibi düşünebilirsiniz.
Karanlık bir sokakta anahtarınızı kaybettiğinizi varsayın, bu anahtarı ararken:
- Ne kadar büyük “adım” atarsanız aradığınız şeyi ıskalama ihtimaliniz artar
- Ne kadar küçük (anahtardan bile küçük) adımlar atarsanız ıskalama ihtimaliniz azalır ama aramanız çok uzun sürer
Öyle bir adım değeri bulmalıyız ki ne çok küçük olup bizi oyalamalı ne de anahtarı ıskalayacak kadar büyük olmalı.
Iteration (İterasyon Sayısı)
Öğrenme iterasyonlar halinde yapılır, gerçek hayatta da tekrar öğrenmeyi pekiştirir. İterasyon döngüsünde:
- İterasyon başlamadan önce vektörler rastgele sayılarla doldurulur
- Her iterasyonda olması gereken değere doğru yakınsar
- Teorik olarak fazla iterasyon eğitim için iyi gibi görünse de bir noktadan sonra ezberlemeye başlar
- Süreyi uzattığı için maliyeti arttırır
Window Size (Pencere)
Window size da önemli parametrelerden birisi, tam olarak ismi gibi davranıyor. Bir odada oturuyorsunuz ve pencereden dışarı bakıyorsunuz, pencere ne kadar geniş olursa dış dünyadan (context) o kadar haberdar olursunuz.
Bir kelimeyi o pencerenin ortasına koyun ve öncesi ve sonrası ile ne kadar ilişkili olduğunu düşünün:
- Eğer pencere büyükse öncesi ve sonrası ile ilişkisini daha iyi anlarsınız
- Eğer çok büyük olursa bu defa bağlamdan koparabilirsiniz, çok alakasız kelimeleri ilişkilendirmiş olursunuz
- Çok az olursa ilişkileri kaçırabilirsiniz
“window” kavram olarak eğitimde de sıkça kullanılır, anlamak önemli.
class WindowSizeDemo { static demonstrateWindowEffect(sentence, windowSize) { const words = sentence.split(' '); const centerIndex = Math.floor(words.length / 2); const centerWord = words[centerIndex];
console.log(`\n=== Window Size: ${windowSize} ===`); console.log(`Cümle: "${sentence}"`); console.log(`Merkez kelime: "${centerWord}" (pozisyon ${centerIndex})`);
const start = Math.max(0, centerIndex - windowSize); const end = Math.min(words.length - 1, centerIndex + windowSize);
const context = []; for (let i = start; i <= end; i++) { if (i !== centerIndex) { context.push(words[i]); } }
console.log(`Context kelimeler: [${context.join(', ')}]`); console.log(`Context büyüklüğü: ${context.length}`);
return context; }
static compareWindowSizes() { const sentence = "React ile frontend geliştirici olmak için JavaScript bilmek gerekiyor";
[1, 2, 3, 5].forEach(windowSize => { this.demonstrateWindowEffect(sentence, windowSize); }); }}
WindowSizeDemo.compareWindowSizes();sigmoid() Fonksiyonu
Word2Vec’in aktivasyon fonksiyonu. Herhangi bir sayıyı 0 ile 1 arasında bir olasılığa çeviriyor. Bu fonksiyon sayesinde “bu kelimeler birlikte geçme olasılığı %80” gibi ifadeler kullanabiliyoruz. Sigmoid’in matematiksel güzelliği türevinin kolay hesaplanması, bu da gradient descent algoritması için kritik önem taşıyor. “gradient descent”e eğitim konusunda hak ettiği kadar değineceğiz, yine önemli bir konu optimizasyon için.
σ(x) = 1 / (1 + e^(-x))Sadece sigmoid fonksiyonuna bakmak istersek:
class SigmoidDemo { static sigmoid(x) { return 1 / (1 + Math.exp(-x)); }
static demonstrateSigmoid() { console.log("=== Sigmoid Fonksiyonu ==="); const testValues = [-5, -2, -1, 0, 1, 2, 5];
testValues.forEach(x => { const result = this.sigmoid(x); console.log(`σ(${x}) = ${result.toFixed(4)}`); });
console.log("\nSigmoid özellikleri:"); console.log("• Negatif değerler → 0'a yakın"); console.log("• Pozitif değerler → 1'e yakın"); console.log("• 0 → 0.5"); console.log("• Smooth gradient (türevlenebilir)"); }}
SigmoidDemo.demonstrateSigmoid();buildVocabulary() Metodu
Corpus’taki tüm biricik kelimeleri buluyor ve her birine rastgele vektörler atıyor. Bu rastgele başlangıç çok önemli çünkü eğitim sürecinde bu vektörler anlamsal ilişkilere göre optimize edilecek. Benim kavramakta zorlandığım bir konu olmuştu bu, sanki tüm kelimelerin bir öntanımlı vektörü var, erğitim ile onlar kullanılıyor sanıyordum fakat tekrar etmekte fayda var, başlangıçta hemen her şey random üretiliyor ve eğitim sürecinde birer “anlam” kazanıyorlar.
generateSkipGramPairs() Metodu
Skip-gram yaklaşımı için training verisi oluşturuyor. Her kelimeyi merkez alıp çevresindeki kelimeleri context olarak eşleştiriyor. “kedi evde uyur” cümlesinde “evde” merkez kelime ise [“evde”→“kedi”] ve [“evde”→“uyur”] pair’leri oluşuyor. Bu pair’ler modele “evde kelimesi kedi ve uyur kelimeleri ile birlikte geçer” bilgisini veriyor.
generateCBOWPairs() Metodu
CBOW yaklaşımı için tam tersini yapıyor. Context kelimelerini alıp merkez kelimeyi tahmin etmeye çalışıyor. [“kedi”, “uyur”] context’inden “evde”yi tahmin etmeye çalışıyor. Bu yaklaşım “hangi kelime bu bağlamda geçebilir?” sorusunu cevaplıyor ve daha sık geçen kelimeler için daha iyi sonuç veriyor.
trainStep() Metodu
Bir training pair’i için tek bir öğrenme adımı gerçekleştiriyor. İşlem sırası:
- Dot Product: Merkez kelime ile context kelimesinin vektörlerini çarpıyor
- Sigmoid: Score’u olasılığa çeviriyor
- Error: Target (1, pozitif sample) ile prediction arasındaki farkı hesaplıyor
- Gradient Descent: Vektörleri error’a göre güncelliyor
Örneğin:
1.step: “kedi” = [0.245, -0.123, 0.456, -0.234]
2.step: “kedi” = [0.278, -0.098, 0.423, -0.201] // Anlamsal yakınlığa göre optimize edildi
Bu süreç binlerce kez tekrarlanarak vektörler optimize ediliyor.
Bu simülasyon gerçek Word2Vec’in çok basitleştirilmiş versiyonu. Gerçek implementasyonda negative sampling, hierarchical softmax gibi optimizasyonlar var ama temel mantık aynı: kelimeleri birlikte geçme istatistiklerine göre vektör uzayında konumlandırmak.
Sonuç: Anlamın Matematik ile Kodlanması
Bu yazıda gördük ki:
- N-gram analizi sıklık tabanlı ama semantik yakınlığı yakalayamıyor
- Sayısal temsiller kelimeleri kıyaslamanın temelini oluşturuyor
- Vektörel temsiller çok boyutlu anlam uzayında konum belirlemeyi sağlıyor
- Distributional hypothesis benzer bağlamlardaki kelimelerin benzer anlamlara sahip olduğunu söylüyor, yapısalcılık 🤘
- Word2Vec ilk defa anlamsal ilişkileri matematik ile kodlamayı başardı
- Model parametreleri (learning rate, window size, vector size) öğrenme kalitesini belirliyor
Word2Vec ile bilgisayarlar ilk defa kelimelerin anlamsal ilişkilerini yakalamayı başardı. “React geliştirici” ile “Frontend geliştirici” arasındaki bağlantıyı kurabilir hale geldi. Vektör aritmetik ile “Kral - Erkek + Kadın ≈ Kraliçe” gibi analojik ilişkileri keşfedebilir hale geldi.
Word2Vec’in Sınırları
Ancak Word2Vec’in önemli bir sınırı var: her kelime için tek bir vektör öğreniyor. “Yer” kelimesi her zaman aynı vektörle temsil ediliyor, ister “güzel bir yer” ister “yemeğini yer” context’inde geçsin.
Bu eşanlamlılık, embedding dünyasında bir sonraki büyük devrimi hazırladı: contextual embeddings.
Bir sonraki yazımızda!